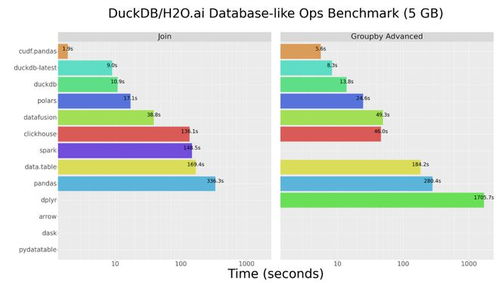
在Python数据科学领域,Pandas长期以来是数据处理与分析的事实标准。随着数据规模的爆炸式增长,其性能瓶颈日益凸显。如今,一个名为Polars的新星正迅速崛起,以其卓越的速度与内存效率,成为处理大规模数据集的有力竞争者。
为什么需要Polars?
Pandas基于NumPy构建,虽然功能强大,但在处理GB级甚至TB级数据时,常受限于单线程运算和内存消耗。Polars则专为现代硬件设计,采用Apache Arrow作为内存模型,并利用Rust语言编写核心引擎,实现了真正的多线程并行计算。
Polars的核心优势
- 闪电般的速度:在基准测试中,Polars的某些操作比Pandas快10倍甚至100倍,尤其在分组聚合、连接操作和大数据过滤场景下表现突出。
- 极致的内存效率:Arrow列式存储大幅减少了内存占用,且支持流式处理,允许处理远超内存大小的数据集。
- 优雅的API设计:提供类似Pandas的易用性,同时引入更一致的链式调用方法,代码更简洁、表达力更强。
- 无缝集成生态:可与NumPy、Pandas互操作,并支持从CSV、Parquet、数据库等多种数据源直接读取。
入门示例:快速体验Polars
`python
import polars as pl
# 读取数据
df = pl.readcsv('largedataset.csv')
# 链式操作:筛选、分组、聚合
result = (df.filter(pl.col('sales') > 1000)
.group_by('category')
.agg(pl.col('revenue').sum()))
# 转换为Pandas DataFrame(如需)
pandasdf = result.topandas()`
何时选择Polars?
- 处理数百万行以上的数据集时
- 需要频繁进行复杂转换与聚合时
- 追求极致性能,减少等待时间时
- 内存有限,需处理超出内存的数据时
平衡之道:Polars与Pandas共存
尽管Polars优势明显,但Pandas凭借其成熟的生态系统和广泛的社区支持,在中小型数据、快速原型开发及教育领域仍不可替代。明智的做法是根据场景灵活选择:
- Polars:生产环境中的大规模数据处理、性能关键型任务。
- Pandas:数据探索、小规模分析、与大量现有Pandas代码库集成。
未来展望
Polars正快速发展,社区日益活跃。其路线图包括更丰富的SQL支持、机器学习集成及更完善的IO功能。对于数据工程师和科学家而言,掌握Polars正成为一种有价值的技能,它不仅是Pandas的补充,更是面向未来大数据挑战的下一代解决方案。
结论:Pandas不会消失,但Polars的出现标志着Python数据处理进入了‘多核并行、内存高效’的新时代。在数据规模不断膨胀的今天,将这个‘神器’加入工具箱,无疑能让你的数据处理工作如虎添翼。