在大数据时代,图表集已成为洞察海量信息、传达复杂洞见的核心工具。任何出色的可视化作品,其基石并非炫目的图形本身,而是背后严谨、高效的数据处理流程。从原始数据到直观图表,数据处理扮演着“翻译官”与“雕刻师”的双重角色,其质量直接决定了最终图表集的信息价值与可信度。
一、数据处理:图表集构建的生命线
数据处理是为图表集准备“合格原料”的系统性工程。原始数据通常存在格式不一、存在缺失值、包含噪声或冗余信息等问题。未经处理的数据直接可视化,轻则导致图表误导观众,重则使得核心趋势与模式被完全掩盖。因此,数据处理的首要目标是实现数据的准确性、一致性、完整性与可用性。
二、核心处理流程:从混沌到清晰
一个典型的、服务于图表集的数据处理流程包含以下关键步骤:
- 数据采集与集成:从数据库、API、日志文件、传感器等多源异构环境中收集数据,并进行初步整合,形成统一的数据池。
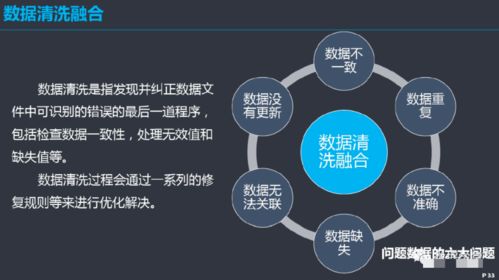
- 数据清洗:这是最具挑战性的环节之一。包括:
- 处理缺失值:根据情况选择删除、填充(如用均值、中位数、众数或通过算法预测)或标记缺失。
- 处理异常值:识别并分析异常点,判断是数据错误还是重要边缘情况,决定是修正、删除还是保留。
- 格式标准化:统一日期、货币、单位等格式,确保数据字段的一致性。
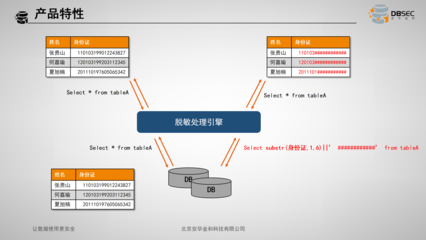
- 去重与纠错:消除重复记录,修正明显的逻辑或录入错误。
- 数据转换与集成:
- 数据转换:对数据进行规范化、离散化、聚合等操作。例如,将连续收入分段为“高、中、低”,或将销售数据按“月”、“季度”进行聚合,以适应不同图表类型的需求。
- 特征工程:创造新的、对可视化分析更有意义的衍生特征。例如,从交易日期中提取“星期几”、“是否节假日”等特征,以便在图表中揭示周期规律。
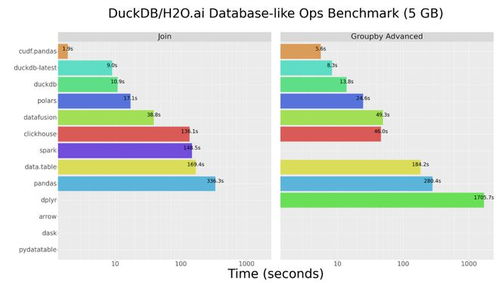
- 数据归约与采样:面对超大规模数据集,直接可视化可能导致性能瓶颈或图表过于密集。此时需通过抽样(如随机抽样、分层抽样)、维度约减(如主成分分析PCA)或数据立方体聚合等方法,在保留数据分布特征的前提下减少数据量。
- 数据结构化:将处理后的数据整理成适合特定图表引擎或库(如ECharts, D3.js, Tableau等)读取的结构,常见的有宽表、长表或特定的JSON格式。
三、服务于可视化目标的处理策略
数据处理并非一成不变,其策略需紧密围绕图表集的最终目标进行调整:
- 探索性分析图表:处理重点在于保留数据的原始分布与细节,避免过度聚合,以便在散点图、直方图中发现潜在模式、关联与异常。
- 解释性/报告性图表:处理重点转向清晰化与强调。需要通过聚合、排序、计算占比/增长率等,突出关键信息和核心故事线,使柱状图、折线图、饼图等能一目了然地传达结论。
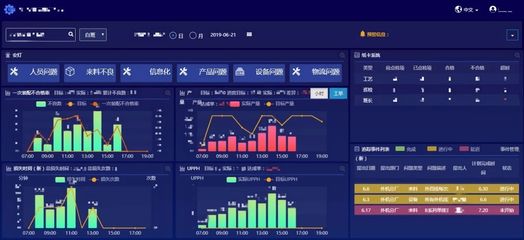
- 交互式仪表板:数据处理需构建多层次、可下钻的数据模型。例如,准备从国家到省份到城市的多级聚合数据,并确保不同图表间的数据字段能够联动和过滤。
四、挑战与最佳实践
挑战:处理流程的自动化与可重复性、实时流数据的处理、处理过程中的数据血缘与质量追踪、平衡数据处理细节与可视化性能。
最佳实践:
1. 流程文档化:详细记录每个处理步骤的逻辑与决策,确保过程可审计、可复现。
- 迭代处理:数据处理与可视化设计应同步迭代。初步图表可能揭示新的数据问题,需要返回处理阶段进行优化。
- 保持数据上下文:在清洗和转换时,务必理解业务背景,避免因技术操作而扭曲业务事实。
- 利用现代工具:借助Python(Pandas, NumPy)、R、SQL或可视化平台内置的数据准备工具(如Tableau Prep, Power Query)来提升处理效率与可靠性。
结论
大数据图表集的魅力,始于精准、深思熟虑的数据处理。它犹如一座桥梁,将杂乱无章的原始数据荒原,转化为信息清晰、脉络分明的可视化绿洲。只有将数据处理视为一项融合了科学严谨性与艺术判断力的核心工作,我们才能确保最终的图表集不仅美观,更能真实、有力、高效地诉说数据背后的故事,驱动明智的决策。