随着大数据与人工智能技术的深度融合,智慧农业已成为现代农业发展的重要方向。针对农产品市场波动性大、供需信息不对称等痛点,设计并实现一个集数据处理、预测分析与智能推荐于一体的综合性系统,具有重要的实践价值。本毕业设计旨在融合Spark、Hadoop、Hive、LLM大模型及Django框架,构建一个先进的智慧农业决策支持系统,核心功能涵盖农产品价格预测、销量预测与个性化推荐。
1. 系统总体架构与核心技术栈
系统采用分层架构设计,以保障高可扩展性与处理能力。
- 数据存储与计算层: 以Hadoop HDFS作为海量农业数据(如历史价格、天气、种植面积、市场交易、电商评论)的分布式存储基础。利用Hive构建数据仓库,进行结构化的数据管理与离线查询,为上层分析提供清洁、整合的数据集。
- 大数据处理与分析层: Apache Spark作为核心计算引擎,凭借其内存计算优势和丰富的库(Spark SQL, MLlib, Streaming),高效完成数据的ETL(抽取、转换、加载)、特征工程,并并行化地训练传统的机器学习预测模型(如回归、时间序列分析)。
- 智能模型层: 引入大型语言模型作为系统的智能增强。一方面,LLM可用于处理非结构化文本数据(如政策新闻、社交媒体舆情、农产品描述),通过微调或提示工程,提取影响价格和销量的语义特征与情感倾向。另一方面,结合传统特征与LLM提取的深层语义特征,构建更精准的融合预测模型。在推荐模块,LLM可深入理解用户查询和农产品特性,生成更人性化、解释性更强的推荐理由。
- 应用与服务层: 采用Django这一高性能Python Web框架搭建后端RESTful API服务,并管理前端展示界面。Django负责接收用户请求(如查询特定农产品预测)、调用Spark/LLM模型服务,并将预测结果、推荐列表可视化呈现给农户、经销商或消费者。
2. 核心功能模块详解
2.1 农产品价格与销量预测系统
这是系统的智能核心。数据处理流程始于Hive中的历史数据整合,经由Spark进行大规模特征计算(如移动平均、周期波动、关联因素量化)。预测模型采用混合策略:
- 基础预测模型: 使用Spark MLlib构建如梯度提升树、随机森林或ARIMA等模型,处理数值型和类别型特征。
- LLM增强分析: 将相关的网络文本信息输入LLM,提取“政策扶持力度”、“市场恐慌情绪”、“消费趋势关键词”等软性指标,作为特征补充。
- 融合与预测: 将传统特征与LLM提取的特征合并,训练最终的集成预测模型,输出未来短期(如一周)和中长期(如一季)的价格区间与销量预估,并通过Django前端以图表形式直观展示。
2.2 农产品智能推荐系统
推荐系统服务于两端:为消费者推荐可能感兴趣的农产品,为生产者推荐有市场潜力的种植品类。
- 协同过滤与内容推荐: 利用Spark MLlib的交替最小二乘法实现基于用户-购买行为的协同过滤。基于农产品的品类、产地、特性等属性进行内容推荐。
- LLM驱动的语义与情境推荐: LLM在此发挥关键作用。它能深度解析农产品的自然语言描述(如“多汁”、“有机种植”),并与用户画像(可能由历史行为或查询文本推断)进行语义匹配。例如,当用户搜索“适合夏天清淡饮食的蔬菜”,LLM可理解其深层需求,并结合时令、气候数据,推荐黄瓜、苦瓜等,并生成自然的推荐解释。
2.3 数据处理与可视化平台
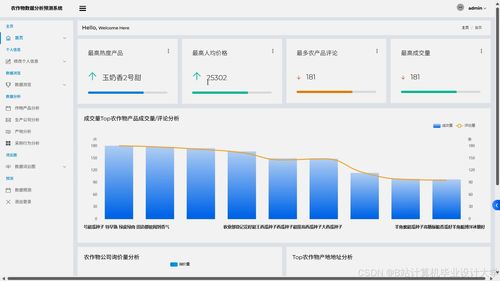
系统通过Django提供统一的数据管理与可视化门户。用户不仅可以查看预测和推荐结果,还能上传本地数据,触发后台的Spark数据处理流水线。系统提供数据看板,动态展示不同区域、不同品类农产品的市场价格走势、预测对比及热销榜单。
3. 技术挑战与创新点
- 挑战: 多源异构数据(数值、文本)的融合处理;LLM大模型与大数据框架的高效集成与部署;预测模型在农业领域的可解释性要求。
- 创新点: 将LLM的深层语义理解能力与传统大数据分析技术(Spark/Hadoop)有机结合,突破了传统预测模型仅依赖结构化数据的局限,实现了“数据+语义”的双轮驱动决策。系统不仅是一个预测工具,更是一个融合了市场情报分析的智慧农业大脑。
4.
本设计提出的系统,通过整合从底层分布式存储到上层智能应用的完整技术栈,构建了一个功能全面、技术先进的智慧农业决策支持平台。它不仅能帮助农业生产者与经营者规避市场风险、优化种植与销售策略,也能为消费者提供更个性化的购物体验,是推动农业数字化转型、实现精准农业与智慧供应链的一次有益探索。该系统架构清晰,模块耦合度低,便于未来进一步集成物联网传感器数据、图像识别等更多技术,拓展其应用边界。