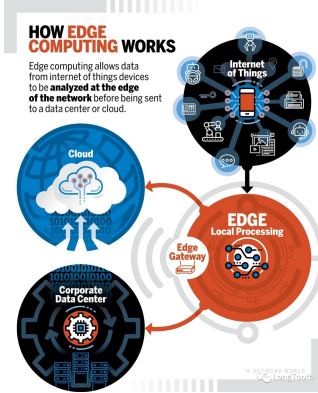
随着物联网、人工智能和5G技术的飞速发展,数据量呈爆炸式增长,数据处理的需求也变得更加复杂和多样。传统的云计算模式已难以满足所有场景,因此催生了雾计算和边缘计算等新模式。理解这三者的区别与联系,关键在于把握数据处理的“位置”与“时机”。
1. 云计算:集中式处理的“大脑”
云计算可以被视为数据处理体系的“中央大脑”。它将海量数据通过网络(通常是互联网)传输到远程的大型数据中心进行集中存储、管理和分析。其核心特点是:
- 集中化与高弹性:资源池化,可按需扩展,处理能力强大。
- 处理复杂分析与长期存储:擅长进行大数据挖掘、机器学习模型训练和非实时性的大规模批处理任务。
- 延迟较高:数据需往返于终端和云端,网络传输延迟不可避免,不适合对实时性要求极高的场景。
典型应用:企业ERP系统、海量视频内容存储与点播、大型电商平台的推荐算法。
2. 雾计算:云与端的“智能路由器”
雾计算可以看作是云计算的延伸和补充,它位于网络边缘(如本地局域网网关、路由器或专用服务器上),更靠近数据源。其角色类似于一个分布式的“智能路由器”或“中间层”。
- 位置中介:在终端设备和云端之间提供一个中间处理层。
- 局部聚合与预处理:对来自多个终端的数据进行过滤、聚合和初步分析,只将有价值或需要深度处理的数据上传至云,大幅减少带宽压力和云端负载。
- 中等延迟与本地决策:能实现比云计算更快的响应,支持一定程度的实时决策。
典型应用:智能工厂中多个生产线的数据实时监控与协调、智慧城市中某个区域的交通灯联网优化。
3. 边缘计算:数据产生的“第一现场”
边缘计算将数据处理完全下沉到数据产生的源头或“最后一公里”,即在终端设备本身或紧邻终端的小型计算节点(如智能摄像头、工业PLC、车载电脑)上进行。它是三者中“最边缘”的一层。
- 极致低延迟与实时性:数据无需远程传输,在本地毫秒级响应,满足最高标准的实时控制需求。
- 高带宽节省与隐私安全:原始数据不必离开本地,减少了网络带宽消耗,同时敏感数据不外传,提升了隐私和安全性。
- 资源受限:受限于设备本身的计算、存储能力,通常处理相对简单的分析和决策。
典型应用:自动驾驶汽车的即时障碍物识别与避让、工业机器人的实时故障检测与停机、智能手机的人脸解锁。
数据处理的分工与协同
理解这三者,不应将其视为互斥的替代关系,而应看作一个协同工作的分层数据处理体系:
- 边缘层:处理最紧急、最敏感、最本地的任务,实现即时响应。
- 雾层:承上启下,管理一定区域内的多个边缘节点,进行数据汇聚和中级分析。
- 云层:作为后台,负责全局性、非实时的大数据洞察、模型优化和长期归档。
例如,在一个自动驾驶系统中:
- 边缘计算:车辆自身的传感器和处理器实时处理路面图像,瞬间做出刹车或转向指令。
- 雾计算:路侧单元收集附近多辆车的局部数据,协调交叉路口的通行顺序,并向车辆发送预警信息。
- 云计算:收集成千上万辆车的数据,用于训练更优的自动驾驶算法,并更新地图和交通模型。
###
简而言之,从云计算到雾计算再到边缘计算,是一个数据处理能力不断从中心向终端“下沉”和“分布”的过程。其驱动力是为了解决海量数据带来的带宽瓶颈、高延迟和隐私安全等挑战。未来的智能系统,将是云、雾、边缘三层架构紧密协同、各司其职的有机整体,共同实现高效、可靠、智能的数据处理。