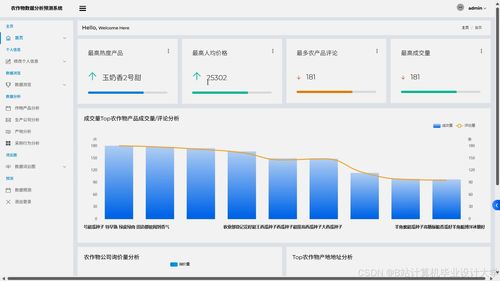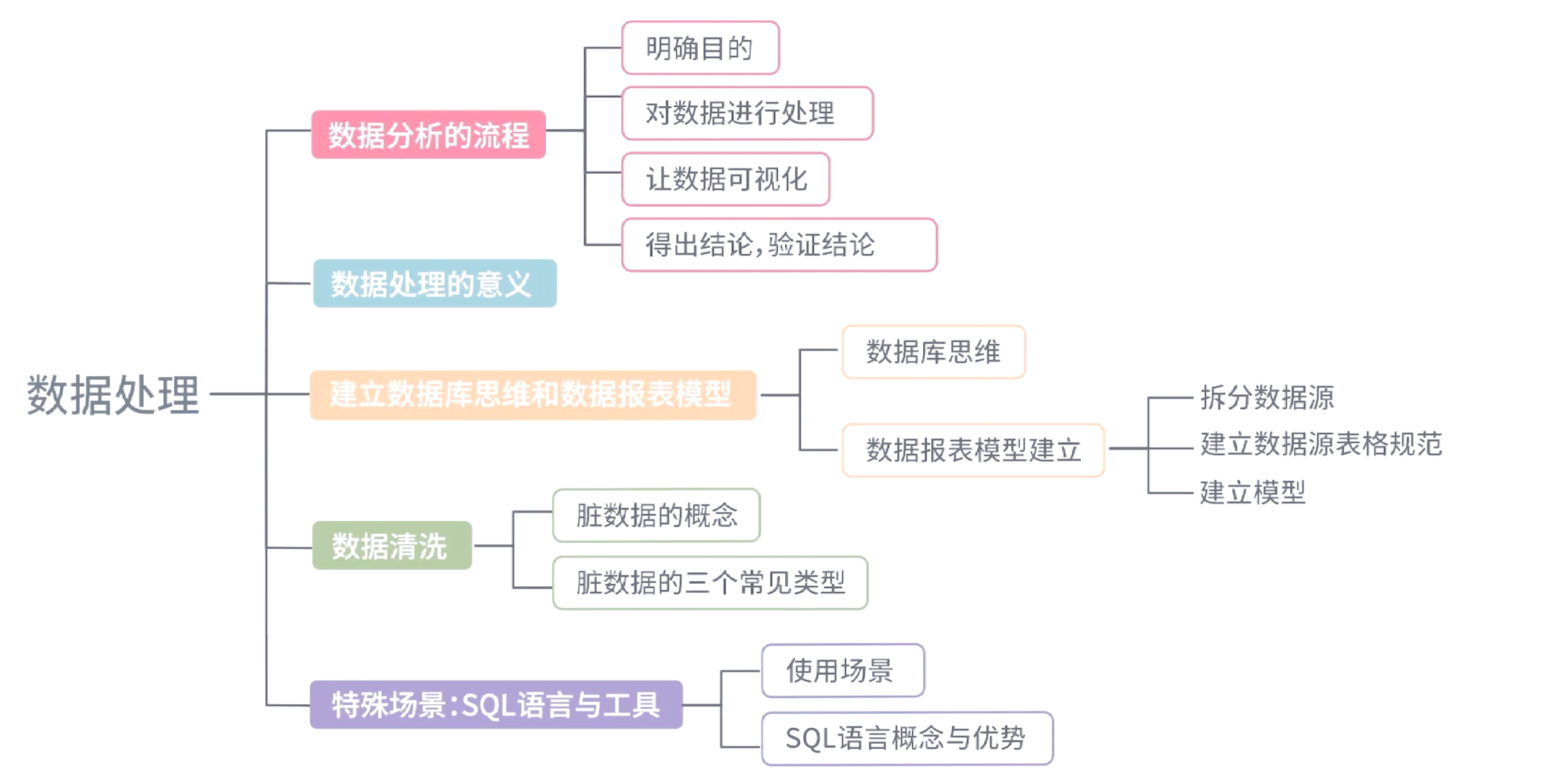
在当今数据驱动的时代,高效处理海量数据已成为企业决策与业务创新的核心需求。众多大数据处理工具应运而生,而Presto作为一款开源的分布式SQL查询引擎,凭借其卓越的性能和灵活的架构,在数据处理领域占据了重要地位。本文将简要介绍Presto的核心概念、架构特点及其在大数据生态系统中的应用价值。
一、Presto的核心定位
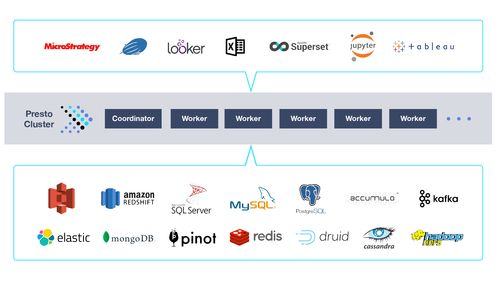
Presto最初由Facebook开发,旨在解决其内部大规模数据分析的性能瓶颈。它并非传统的数据库,而是一个专为交互式分析查询设计的引擎。其核心优势在于能够对多种数据源(如HDFS、Hive、Cassandra、MySQL等)进行联邦查询,用户可以使用标准的SQL语法,跨源联合分析存储在异构系统中的数据,无需进行复杂的数据迁移或转换。
二、架构与工作原理
Presto采用主从(Master-Slave)架构,主要由以下两个核心组件构成:
- 协调者(Coordinator):作为主节点,负责接收客户端查询请求、解析SQL语句、生成并优化执行计划,并将任务分发给工作节点。它还负责管理所有工作节点的状态并协调查询的执行过程。
- 工作节点(Worker):作为从节点,负责具体执行协调者分配的任务,即处理数据块并进行实际的计算。多个工作节点并行工作,共同完成一个查询任务。
Presto的执行引擎采用了独特的“内存中”并行处理模型。查询被分解成多个阶段(Stage),每个阶段又包含多个任务(Task),这些任务在不同工作节点上并行执行,数据通过流水线在任务间流动,最大限度地减少了磁盘I/O,从而实现了极快的查询速度,尤其适合交互式分析场景。
三、关键特性与优势
- 高性能与低延迟:通过内存计算、流水线执行和动态编译等优化技术,Presto能够在秒级甚至亚秒级完成对TB级数据集的查询。
- 联邦查询能力:支持连接多个外部数据源进行关联查询,实现了数据的虚拟化集成,打破了数据孤岛。
- 标准SQL支持:兼容ANSI SQL,降低了数据分析师的学习和使用门槛。
- 弹性扩展:架构无状态,可以轻松通过增加工作节点来水平扩展集群,以应对不断增长的数据量和查询负载。
- 与生态系统无缝集成:与Hive Metastore兼容良好,可以方便地查询Hive表;同时支持连接Kafka、Redis等多种数据系统。
四、典型应用场景
Presto广泛应用于交互式数据仓库查询、即席分析(Ad-hoc Analysis)、多源数据联合报表以及数据探索等场景。例如,分析师可以直接使用SQL对存储在HDFS上的历史数据与实时流入Kafka的日志数据进行关联分析,快速获得业务洞察。
五、与展望
作为大数据处理栈中的重要一环,Presto以其速度、灵活性和易用性,成为了企业构建实时数据分析平台的优选引擎之一。随着云原生技术的发展,Presto也在持续演进,如由Presto原核心团队创建的Trino项目(原PrestoSQL),正进一步推动其社区生态的繁荣。随着数据量的持续爆炸式增长和实时性要求的不断提高,Presto及其衍生技术将在数据处理与分析领域发挥更加关键的作用。