在当今快速变化的市场环境中,精准预测供应链需求是企业实现降本增效、提升竞争力的关键。机器学习技术凭借其强大的数据挖掘与模式识别能力,已成为供应链需求预测领域的重要工具。其应用核心在于构建一个从数据到洞见的闭环流程,而时间序列数据的处理则是这一流程的基石。
一、机器学习预测供应链需求的核心流程
一个典型的机器学习预测流程通常包含以下关键步骤:
- 问题定义与目标设定:明确预测目标(如未来一周的日需求量、月度总销量等)、预测粒度(SKU级别、品类级别)和业务指标(如预测准确率、平均绝对误差)。
- 数据收集与整合:汇集多源异构数据,这是模型成功的燃料。数据通常包括:
- 历史需求数据:核心的时间序列数据。
- 产品特征:品类、价格、生命周期阶段、促销信息等。
- 外部因素:季节性、节假日、天气、宏观经济指标、竞争对手活动、社交媒体情绪等。
- 供应链内部数据:库存水平、交货周期、补货策略等。
- 模型选择与训练:
- 传统时间序列模型:如ARIMA、指数平滑法(ETS),适用于具有明显趋势和季节性的单变量序列。
- 机器学习模型:如随机森林、梯度提升树(如XGBoost, LightGBM),能有效融合多源特征,处理非线性关系。
* 深度学习模型:如LSTM(长短期记忆网络)、Transformer,特别擅长捕捉长期依赖和复杂的时间动态模式,适用于海量、高维数据。
模型选择需在复杂性、可解释性、计算成本和预测精度间取得平衡。
- 模型评估与部署:使用留出法或时间序列交叉验证评估模型在“未来”数据上的表现。将表现最佳的模型部署到生产环境,实现自动化、周期性的预测。
- 监控与迭代:持续监控预测误差,当误差超出阈值或业务环境发生重大变化时,触发模型重训练或调整,形成持续优化的闭环。
二、时间序列数据处理的关键环节
时间序列数据是需求预测的核心输入,其处理质量直接决定模型性能。主要处理步骤包括:
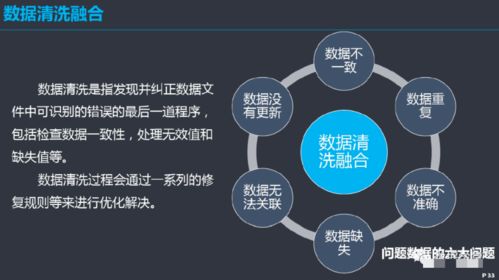
- 数据清洗:
- 处理缺失值:对于时间序列,可采用前向填充、后向填充、线性插值或基于序列模型(如ARIMA)预测填充。需谨慎处理,避免引入偏差。
- 识别与处理异常值:供应链数据常因促销、缺货、系统错误等产生异常点。可使用统计方法(如3σ原则)、孤立森林或业务规则进行识别,并根据成因决定是修正、剔除还是保留。
- 特征工程:这是提升模型预测能力的关键。
- 时间特征:从时间戳中提取小时、星期几、月份、季度、是否为节假日/周末等。
- 滞后特征:创建历史同期值(如一周前、一月前、一年前的需求)作为特征,帮助模型捕捉短期依赖和季节性。
- 滚动统计特征:计算过去一段时间窗口内的均值、标准差、最大值、最小值等,反映近期趋势和波动。
- 序列分解:将原始序列分解为趋势、季节性和残差成分,可分别进行预测或作为特征。
- 外部特征融合:将促销标记、天气指数等作为额外特征向量与时间序列对齐。
- 平稳化处理:许多模型假设数据是平稳的(均值和方差不随时间变化)。对于非平稳序列(有明显趋势或季节性),常用方法包括:
- 差分:计算连续观测值之间的差异,是去除趋势的常用方法。
- 对数变换:稳定方差,尤其适用于呈指数增长的趋势。
- 季节性差分:去除季节性成分。
- 数据分割:时间序列数据必须按时间顺序分割,以确保“未来”数据不泄露到训练集中。通常按时间点将数据划分为训练集、验证集(用于调参)和测试集(用于最终评估)。
- 归一化/标准化:将特征缩放到相近的尺度,有助于加速模型收敛并提升性能,特别是对于距离敏感的模型(如KNN、神经网络)。常用方法有Min-Max归一化和Z-Score标准化。
###
运用机器学习预测供应链需求是一个系统性的工程。其成功不仅依赖于先进的算法,更依赖于对业务的理解和高质量的数据处理。其中,对时间序列数据进行彻底的清洗、创造性的特征工程以及符合时序规律的建模流程,是构建一个稳健、精准预测系统的核心。企业应从业务实际出发,从小范围试点开始,逐步构建数据驱动、持续迭代的智能预测能力,从而在复杂的供应链网络中赢得先机。