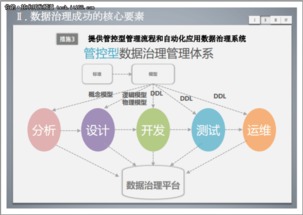
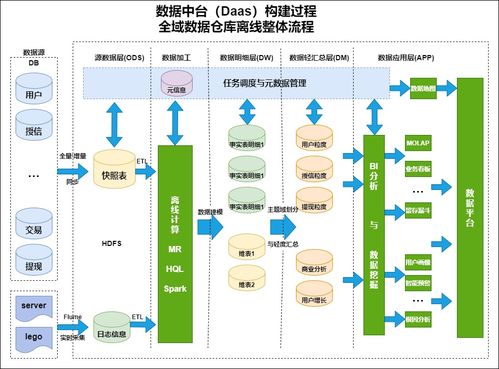
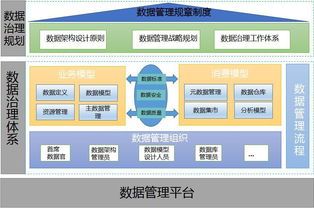
在数字化转型浪潮席卷全球的当下,企业数据量呈指数级增长,运维数据的复杂性、多样性和实时性要求日益提升。传统的单一、孤岛式的运维数据分析平台已难以满足现代企业对于统一监控、智能分析和快速响应的需求。爱数AnyRobot作为领先的智能运维与可观测性平台,近期基于创新的Hub(中心枢纽)架构,实现了对Splunk数据的有效纳管与融合处理,标志着运维数据处理范式的一次重要革新,为企业构建统一、智能的数据运维中心提供了强大引擎。
一、 挑战与机遇:为何需要纳管Splunk数据?
Splunk作为早期进入市场的机器数据分析平台,在全球范围内拥有广泛的企业用户基础,积累了海量的历史日志、指标和事件数据。这些数据是企业IT环境健康状况、安全态势和业务运行情况的宝贵记录。随着技术栈的多元化(云原生、微服务、容器化)和成本优化需求的增长,企业往往面临以下挑战:
- 成本高企:Splunk的许可模式随着数据量增长而成本陡增。
- 架构局限:传统架构在应对超大规模、实时流式数据处理时可能存在弹性与效率瓶颈。
- 生态融合难:与企业内部新兴的观测数据源、国产化平台或特定场景分析工具集成复杂,易形成新的数据孤岛。
因此,在不抛弃历史数据资产的前提下,寻求一个更开放、更具性价比、处理能力更强的统一平台来纳管并深度利用这些数据,成为众多企业的迫切需求。爱数AnyRobot的Hub架构正是为此而生。
二、 核心创新:Hub架构的解耦与协同优势
AnyRobot的Hub架构设计精髓在于“解耦”与“协同”。它将数据采集、数据处理、数据存储和数据分析等核心能力模块化,并通过统一的中心枢纽进行调度和管理。在纳管Splunk数据的场景下,这一架构展现出独特优势:
- 统一接入与纳管:Hub作为中心调度点,可以无缝接入来自Splunk的历史数据(通过API、文件导出等方式)以及实时数据流。它打破了源端系统的边界,将Splunk数据与其他数据源(如APM、NPM、基础设施监控、业务日志等)置于同一套管理框架下。
- 数据处理流水线化:纳管后的数据进入AnyRobot强大的数据处理流水线。Hub架构允许动态配置数据解析、清洗、丰富、脱敏、归一化等处理规则。例如,将Splunk中的原始日志格式与来自其他系统的日志进行字段统一,为后续的关联分析奠定基础。
- 弹性存储与计算分离:得益于架构解耦,AnyRobot可以采用更具成本效益的存储方案(如对象存储)来长期归档海量Splunk历史数据,同时利用高性能的索引存储满足热数据的快速检索。计算资源也可以根据分析任务的需求独立弹性伸缩,克服了传统一体架构的资源争用问题。
- 智能分析能力注入:Hub将纳管的数据统一输送至AnyRobot的智能分析引擎。这意味着原本在Splunk中的数据,现在可以轻松利用AnyRobot内置的机器学习算法进行异常检测、根因分析、趋势预测,或与可观测性数据进行全链路追踪关联,获得更深入的洞察。
三、 实践路径:如何实现平滑纳管与数据处理
爱数AnyRobot纳管Splunk数据并非简单的数据迁移,而是一个循序渐进的融合过程:
- 评估与规划阶段:分析现有Splunk的数据类型、量级、访问频率及关键用例。确定首批纳管的数据范围(如核心应用日志、安全事件日志)和纳管模式(全量历史迁移+增量实时同步,或仅同步增量数据)。
- 连接与接入阶段:利用AnyRobot Hub提供的丰富连接器或自定义接口,建立与Splunk实例的安全连接。配置数据拉取或接收策略,确保数据持续、稳定地流入AnyRobot平台。
- 数据处理与建模阶段:在AnyRobot中针对纳管的Splunk数据定义解析规则(Parsing),提取关键字段。建立统一的数据模型(Schema),将Splunk事件字段映射到企业通用的运维数据模型中,实现与来自其他源的数据的“同声翻译”。
- 融合分析与价值释放阶段:基于统一的数据湖,运维团队可以:
- 进行跨源关联分析:将一个来自Splunk的应用程序错误日志,与来自APM的代码级性能指标、来自基础设施的服务器资源利用率进行时间序列关联,快速定位根因。
- 应用智能告警:利用AnyRobot的机器学习,对纳管的Splunk数据流建立动态基线,实现比传统阈值告警更精准、更提前的异常预警。
- 构建统一仪表盘:在单一玻璃面板上,同时展现源自Splunk的历史趋势图与当前其他系统的实时状态,形成完整的业务服务视图。
- 优化成本与归档:将访问频次低的Splunk历史数据自动沉降至低成本存储,同时保持可检索性,显著降低总体拥有成本(TCO)。
四、 未来展望:构建面向未来的智能运维数据生态
爱数AnyRobot基于Hub架构纳管Splunk,其意义远超一个数据迁移项目。它代表了一种以数据为中心、开放融合的智能运维新思路:
- 保护历史投资:尊重并最大化利用现有数据资产。
- 拥抱开放生态:通过Hub架构,AnyRobot未来可以同样优雅地纳管各类异构数据源,成为企业真正的运维数据“集线器”。
- 驱动持续智能:统一的数据基础是高级AIOps应用(如自动根因定位、预测性维护)的燃料,赋能运维从“被动响应”走向“主动预防”和“自主修复”。
爱数AnyRobot通过Hub架构创新性地解决Splunk数据纳管难题,不仅为企业提供了平滑的演进路径和显著的成本效益,更重要的是,它为企业搭建了一个面向未来、弹性灵活、智能驱动的统一运维数据分析平台,助力企业在数字化竞争中赢得先机。