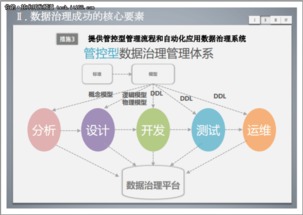
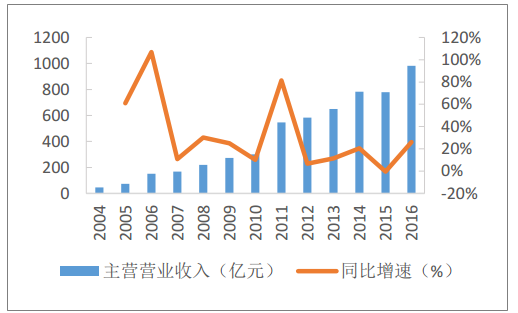
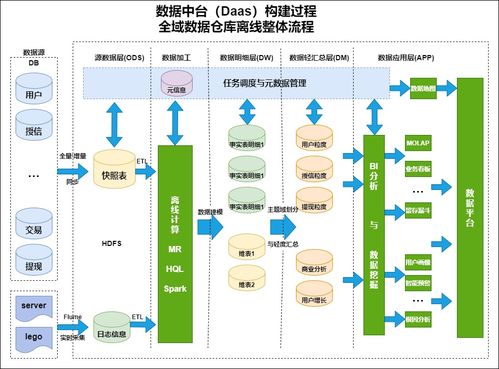
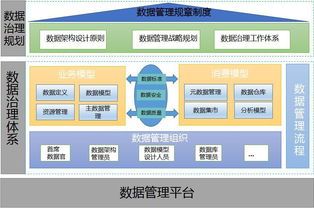
随着数字化转型的深入,大数据系统已成为企业决策与业务创新的核心引擎。其中,数据采集作为大数据生命周期的起点,其架构设计的优劣直接影响后续数据处理的效率与质量。本文将深入剖析大数据系统数据采集产品的典型架构,并阐述其与下游数据处理环节的紧密联系。
一、 数据采集产品的核心架构分析
一个成熟的大数据采集产品通常采用分层、模块化的架构设计,以确保高扩展性、高可靠性与易用性。其核心架构可概括为以下几个层次:
1. 数据源连接层:
这是架构的“触手”,负责与各类异构数据源建立连接。它支持多种连接协议和接口,例如:
- 日志与文件:通过Agent(代理)实时监控并采集服务器日志、应用日志以及各类结构化/半结构化文件。
- 数据库:通过JDBC/ODBC、变更数据捕获(CDC)技术实时或批量同步关系型数据库(如MySQL、Oracle)及NoSQL数据库的数据。
- 消息队列:从Kafka、RocketMQ等消息中间件中消费流式数据。
- API接口:调用第三方公开API或企业内部API获取数据。
* 物联网与传感器:通过特定协议接收设备上报的时序数据。
该层的关键在于适配器的丰富程度与连接稳定性。
2. 采集引擎与传输层:
这是架构的“心脏”,负责数据的抓取、初步过滤与传输。根据数据时效性要求,主要分为两种模式:
- 批量采集:按固定周期(如每小时、每天)全量或增量拉取数据,适用于对实时性要求不高的场景。架构上通常采用分布式调度框架(如Apache DolphinScheduler, Airflow)协调任务。
* 实时流式采集:基于事件驱动,数据产生即被捕获并传输,保障低延迟。常使用Apache Flume、Logstash或自研的轻量级Agent实现,并通过Kafka等高吞吐消息队列进行缓冲与传输。
此层核心挑战在于应对数据源波动、保证断点续传与 Exactly-Once(精确一次)或 At-Least-Once(至少一次)的语义保障。
3. 配置管理与控制层:
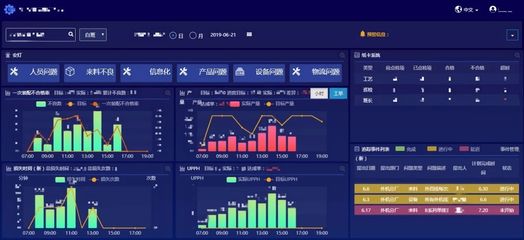
这是架构的“大脑”,提供集中式的可视化控制台。用户在此配置数据源信息、采集任务(如频率、过滤条件)、数据格式转换规则以及监控告警策略。该层将配置下发给分布式运行的采集Agent或任务,并统一收集运行状态、流量指标与错误日志,实现对整个采集管道的可观测性。
4. 缓冲与序列化层:
这是架构的“减震器”,用于解耦采集与处理,应对流量峰值。采集到的数据通常会被序列化(如Avro、Protobuf、JSON)后暂存于高吞吐的分布式消息队列(如Kafka、Pulsar)或分布式日志存储中。这不仅平滑了数据流,也为后续多消费者并行处理提供了可能。
二、 从采集到处理:数据的流转与转换
数据采集的终点,正是数据处理的起点。两者通过清晰的接口和协议无缝衔接。
1. 数据接入与标准化:
数据处理系统(如实时计算平台Flink、Spark Streaming或批处理平台Hive、Spark)从缓冲层(如Kafka Topic)订阅数据。首要步骤是对采集来的原始数据进行解析与标准化,包括:
- 格式解析:将二进制或文本流反序列化为内部数据结构。
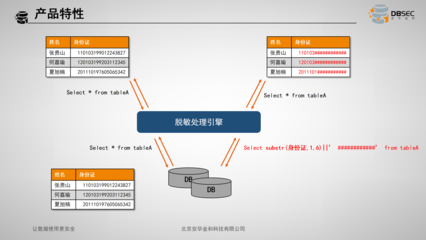
- Schema提取与校验:识别数据模式,确保其符合预期,对格式错误的数据进行分流处理。
- 时间戳提取与规范化:统一事件时间,为基于时间的窗口计算打下基础。
2. 核心数据处理流程:
标准化后的数据进入核心处理管线,主要任务包括:
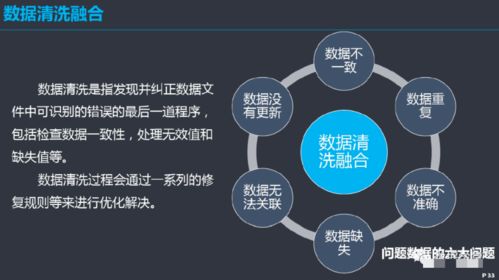
- 数据清洗:过滤无效、重复数据,填补缺失值,修正明显错误。
- 数据转换:进行字段拆分、合并、衍生,执行聚合(求和、计数、平均值)、关联(Join)等复杂计算。
* 数据丰富:关联维表或调用外部服务,为数据打上更多业务标签。
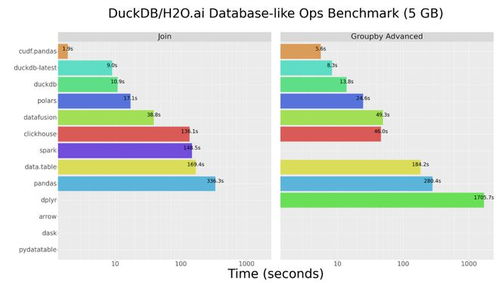
实时处理注重低延迟和流式状态管理,批处理则侧重于高吞吐和复杂分析。现代数据处理架构常采用 Lambda架构 或 Kappa架构 来协同处理实时与批量需求。
3. 数据加载与存储:
处理后的结果数据被加载到不同的存储系统中,以供应用消费:
- 实时指标/事件:写入OLAP数据库(如ClickHouse、Druid)或缓存(如Redis),支持实时监控与交互式查询。
- 明细数据:写入数据湖(如HDFS、S3)或数据仓库(如Hive、Snowflake),供离线分析与模型训练。
- 索引数据:同步至搜索系统(如Elasticsearch),提供全文检索能力。
三、 架构演进与核心考量
当前,数据采集与处理架构正朝着云原生、全托管、智能化的方向演进。Serverless采集任务、基于Kubernetes的弹性调度、以及利用机器学习自动进行数据质量检测与分类,正在成为新的趋势。
在设计或选型时,需重点考量:
- 端到端延迟与吞吐量:能否满足业务SLA要求。
- 数据一致性保障:确保数据不丢、不重、不乱序。
- 可扩展性与弹性:能否平滑应对数据量的快速增长与突发流量。
- 运维复杂度与成本:系统的可观测性、故障自愈能力及资源利用效率。
结论:大数据采集产品与数据处理流程构成一个有机整体。一个优秀的采集架构,通过灵活适配多源、稳定高效传输、集中智能管控,为下游处理提供了高质量、高时效的“原料”。而高效的数据处理则将这些“原料”转化为驱动业务价值的“信息燃料”。二者协同设计,方能构建坚实的数据基石,赋能企业智能化升级。