数据仓库作为企业数据分析的核心基础设施,其发展历程经历了从传统架构到现代云原生技术的演进。海山数据库(He3DB)作为新一代数据仓库解决方案,其设计理念和技术架构深刻吸收了传统数据仓库的经验与教训。本文作为系列文章的第一部分,将聚焦传统数据仓库的数据处理模式,为理解He3DB的架构演进奠定基础。
传统数据仓库诞生于20世纪80年代末至90年代初,其核心目标是整合企业内部分散的异构数据源,构建统一的数据视图以支持决策分析。在数据处理层面,传统数仓遵循经典的ETL(Extract-Transform-Load)流程:首先从业务系统(如ERP、CRM等)抽取数据,然后进行清洗、转换和集成处理,最终加载到专门优化的数据存储中。这种批处理模式通常以夜间作业的形式进行,确保第二天上班前完成数据更新。
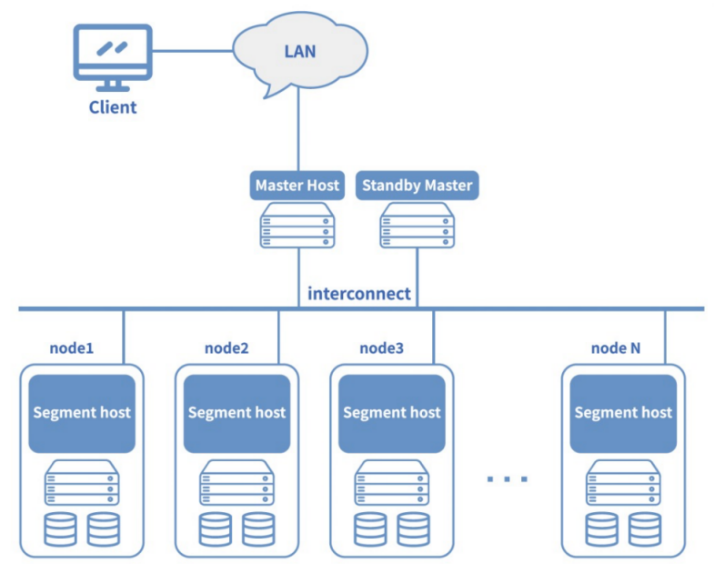
在技术架构上,传统数仓多采用集中式的存储与计算耦合设计。典型代表包括Teradata、Oracle Exadata等一体机解决方案,它们通过大规模并行处理(MPP)架构提升查询性能。数据处理的核心挑战集中在以下几个方面:数据延迟问题突出,T+1的数据更新频率难以满足实时分析需求;扩展性受限,硬件升级成本高昂且存在性能瓶颈;数据类型支持单一,主要针对结构化数据,难以处理半结构化和非结构化数据。
传统数仓的数据建模通常采用维度建模方法,以星型模式或雪花模式组织数据。这种设计虽然提升了查询效率,但也导致了数据冗余和维护复杂性。在数据治理方面,传统数仓建立了严格的数据质量管控流程,但往往缺乏灵活的数据探索和即席查询能力。
随着大数据时代的到来,传统数据仓库在应对海量数据、实时分析和多样化数据类型方面逐渐显现出局限性。正是这些挑战催生了新一代数据仓库技术的创新,也为海山数据库(He3DB)的架构设计提供了重要参考。在后续文章中,我们将深入探讨He3DB如何基于这些传统架构的洞察,构建更现代化、更高效的数据处理体系。