大数据到底怎么学:以数据处理为核心的系统化路径
随着数据成为新时代的“石油”,掌握大数据技能已成为众多从业者提升竞争力的关键。面对庞杂的技术栈和快速迭代的工具,许多学习者容易陷入误区,或盲目跟风,或停滞不前。本文将从数据科学的基本框架出发,聚焦数据处理这一核心环节,澄清常见的学习误区,为你勾勒一条清晰、高效的大数据学习路径。
一、数据科学概论:理解全景图
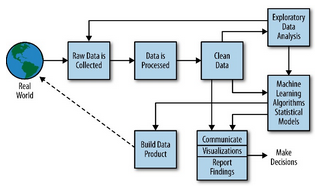
数据科学是一个跨学科的领域,它结合了统计学、计算机科学和特定领域的专业知识,旨在从数据中提取洞见并创造价值。一个经典的数据科学流程(如CRISP-DM)通常包括:
- 业务理解:明确要解决的商业或研究问题。
- 数据获取与理解:收集相关数据并进行初步探索。
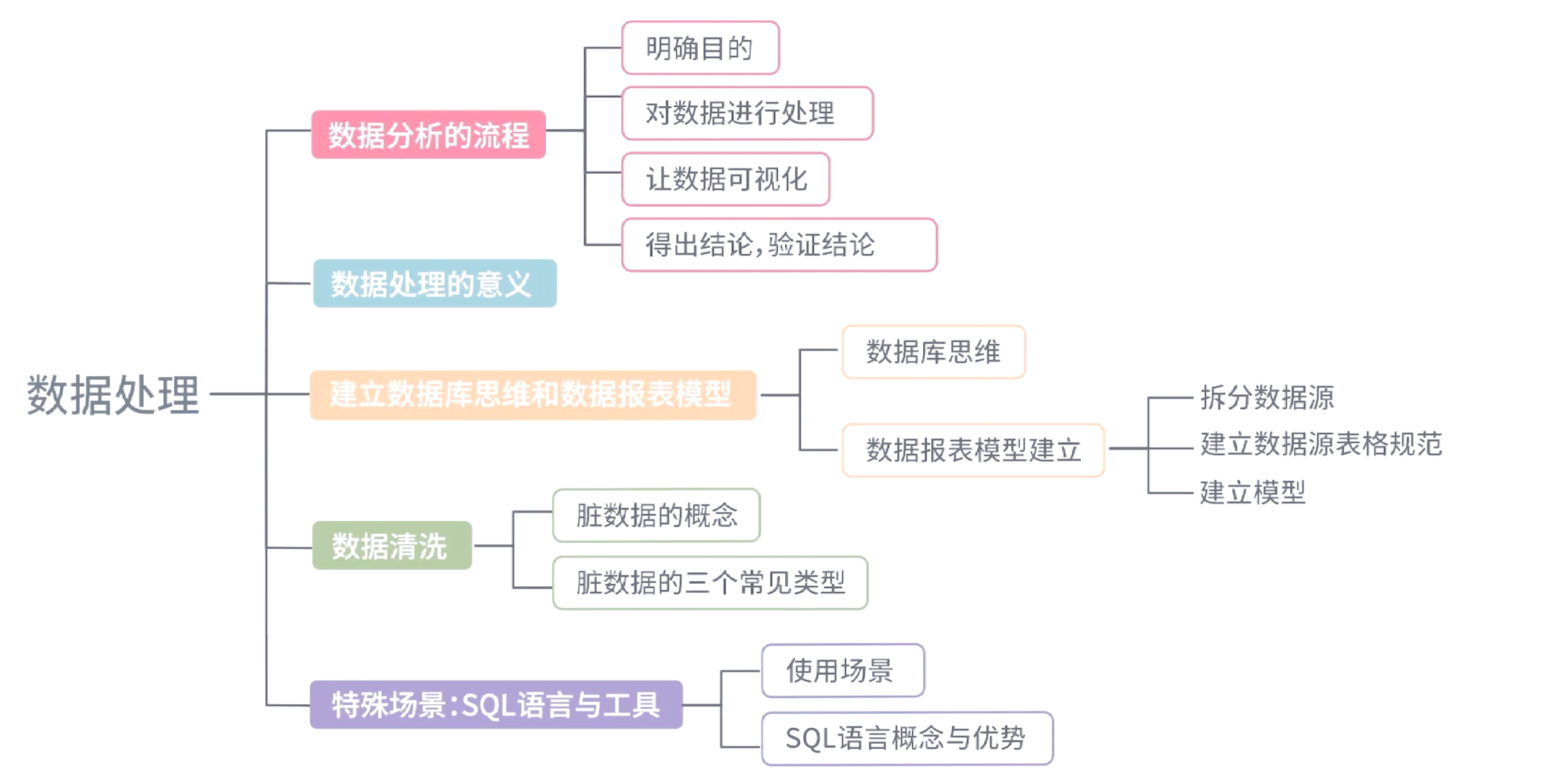
- 数据准备(数据处理):这是承上启下的核心步骤,包括数据清洗、集成、转换、规约等,旨在将原始数据转化为适合建模的格式。
- 建模:应用算法构建模型。
- 评估:验证模型的有效性。
- 部署:将模型投入实际应用。
可见,数据处理的质量直接决定了后续所有环节的上限。没有干净、可靠的数据,再精巧的模型也是“垃圾进,垃圾出”。
二、大数据学习的核心:深入掌握数据处理
数据处理是大数据技术栈的基石。学习时应分层递进:
1. 基础层:编程与SQL
Python/R:这是数据科学的通用语言。重点学习用于数据处理的库,如Python的Pandas(数据操作)、NumPy(数值计算)。
SQL:用于从数据库中高效提取和初步处理数据。这是与数据对话的必备技能,无论技术如何演进,其地位不可动摇。
2. 核心层:大数据处理框架与平台
Hadoop生态:理解其分布式存储(HDFS)和计算(MapReduce)的基本思想。
Spark:作为当前的主流,重点学习其核心抽象(RDD、DataFrame/Dataset)和使用PySpark或Spark SQL进行大规模数据处理。相比MapReduce,Spark在内存计算上的优势使其成为数据处理的首选工具之一。
* 数据仓库与湖仓一体:了解Hive、ClickHouse、Snowflake等概念,理解如何为分析而组织和处理数据。
3. 实践层:工程化与流程管理
学习使用Airflow等工具编排数据处理流水线(ETL/ELT)。
了解数据质量监控、版本控制(如Delta Lake)等生产级数据处理所需的知识。
三、必须规避的常见大数据学习误区
误区一:重模型,轻数据。
盲目追求最新的深度学习模型,却忽视了占项目80%时间的数据处理工作。务必树立“数据第一”的观念,扎实练好数据清洗、特征工程等基本功。
误区二:重工具,轻原理。
沉迷于学习各种新工具的名词,却不理解分布式计算、并行处理、列式存储等底层原理。这会导致遇到复杂问题时无从下手。建议在学习Spark等工具时,同步理解其架构思想和设计原理。
误区三:缺乏系统性,碎片化学习。
东学一点SQL,西看一点Spark教程,知识无法串联。建议以一个完整的项目(如“从日志数据中分析用户行为”)驱动学习,覆盖从数据采集、清洗、存储、处理到可视化的全流程。
误区四:脱离业务场景。
技术学习与实际问题脱节。数据处理的方法千变万化,其目标始终是服务于业务分析或模型构建。在学习每个技术点时,多问一句“这解决了什么业务痛点?”
误区五:忽视数据治理与伦理。
只关注技术实现,不考虑数据安全、隐私保护、偏见消除等问题。这是专业数据科学家与普通技术员的区别所在。
四、推荐的学习路径与心态
- 夯实基础:花足够时间精通Python(Pandas)和SQL。这是你行走数据世界的“双腿”。
- 原理先行:在学习Hadoop/Spark前,先理解分布式系统基础概念。
- 项目驱动:找感兴趣的数据集(如Kaggle、公开政府数据),完成一个端到端的项目,将数据处理作为项目的核心环节来重点实践。
- 深入核心:选择Spark作为重点,深入学习其API和优化技巧,理解其在内存中完成数据处理的强大之处。
- 构建知识体系:将数据处理技能与数据存储(HDFS、HBase)、资源管理(YARN)、调度(Airflow)等周边知识连接起来。
- 保持好奇与批判:关注行业动态,但同时批判性地看待新技术,判断其是否真正解决了数据处理中的效率或质量瓶颈。
学习大数据没有捷径,但可以有清晰的路线图。请牢记,数据处理是这条路上的枢纽站。避开常见误区,沉下心来打好基础,通过实践将原理、工具和业务串联起来,你便能稳步构建起坚实的大数据能力大厦,从而真正驾驭数据,创造价值。